고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
Python
try #1 그냥 생각해서 짠 코드
def solution(participant, completion):
answer = ''
for i in participant:
if i not in completion:
answer=i
elif participant.count(i) > completion.count(i):
answer=i
return answer정확성 통과 O
효율성 통과 X (시간 초과)
해시가 많은 저장공간을 차지하지만, 속도면에서는 빠르기 때문에 해시를 사용해야 효율성 문제를 해결할 것 같다.
python에서 key:value 쌍을 가지는 dictionary로 해시 표현
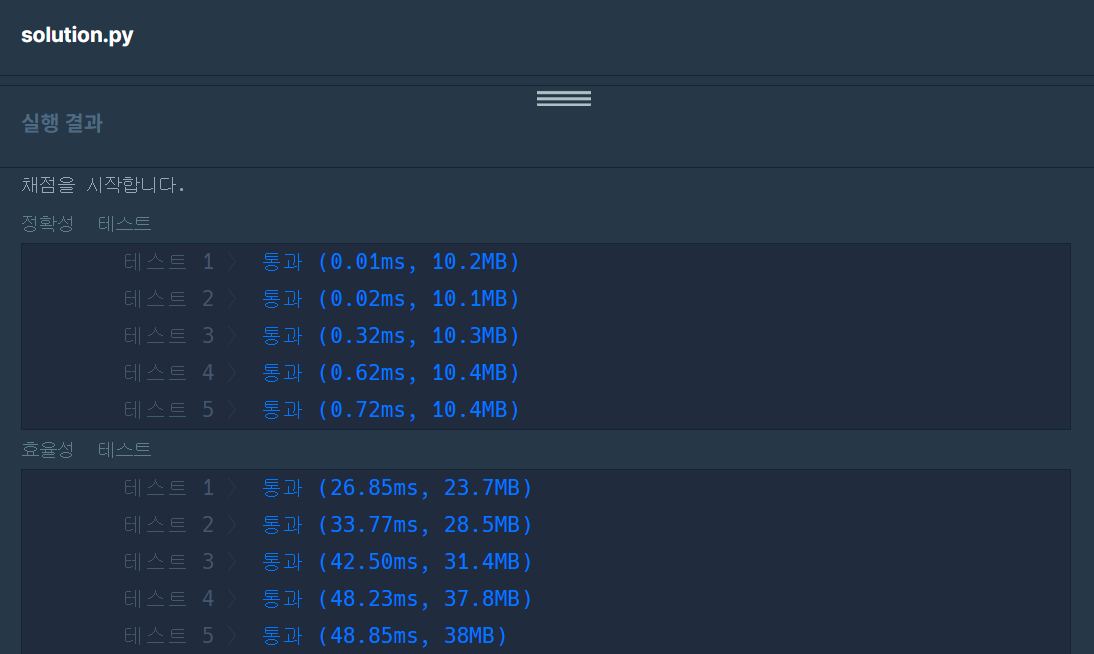
try #2 정렬 후 찾기 (정확성 테스트 통과, 효율성 테스트 통과)
def solution(participant, completion):
participant=sorted(participant)
completion=sorted(completion)
for i in range(len(completion)):
if participant[i] != completion[i]:
return participant[i]
return participant[-1]C++ 정렬 후 탐색을 통과한 후, 그대로 python에 적용했는데 python에서도 정확성과 효율성 모두 통과했다.
python에서는 인덱스 -1이 마지막 원소를 나타내는 것을 활용했다.
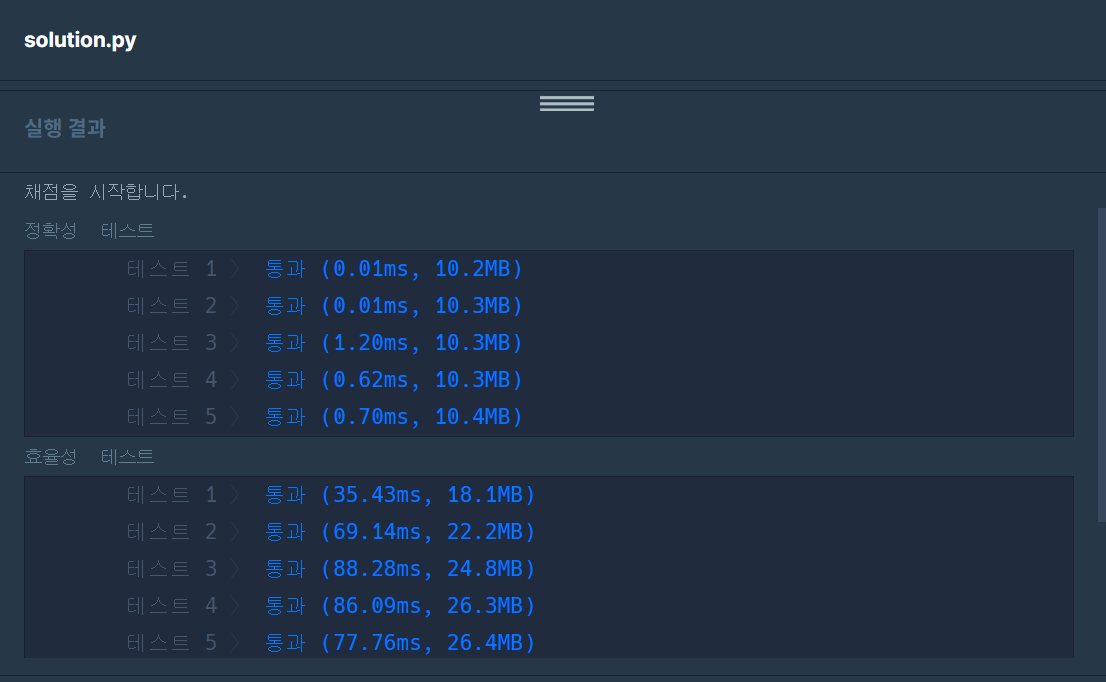
try #3 collections의 Counter 객체 (정확성 통과, 효율성 통과)
collections 라이브러리 내 Counter 객체는 각 원소의 개수에 대한 value를 쌍으로 저장한다.

따라서 각 선수 이름의 수에 대한 카운팅은 Counter로 해결이 가능하고, Counter의 경우 빼기도 가능해서 difference를 비교하는데 편하다.
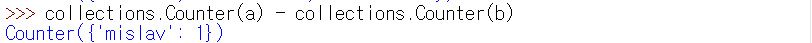
특히 이 문제의 경우, 항상 하나 차이나므로 그 차이는 완주하지 못한 선수이기 때문에 빼서 남은 것을 리턴하면 된다.

반환 시에는 Counter 객체이기 때문에 Counter 내 key를 가지고 오면 dict_keys 객체로 가져오고, 이 element를 가져오고 싶으면 list로 변환 후 첫 번째 원소를 가져와야 한다.

import collections
def solution(participant, completion):
answer= list((collections.Counter(participant)-collections.Counter(completion)).keys())
return answer[0]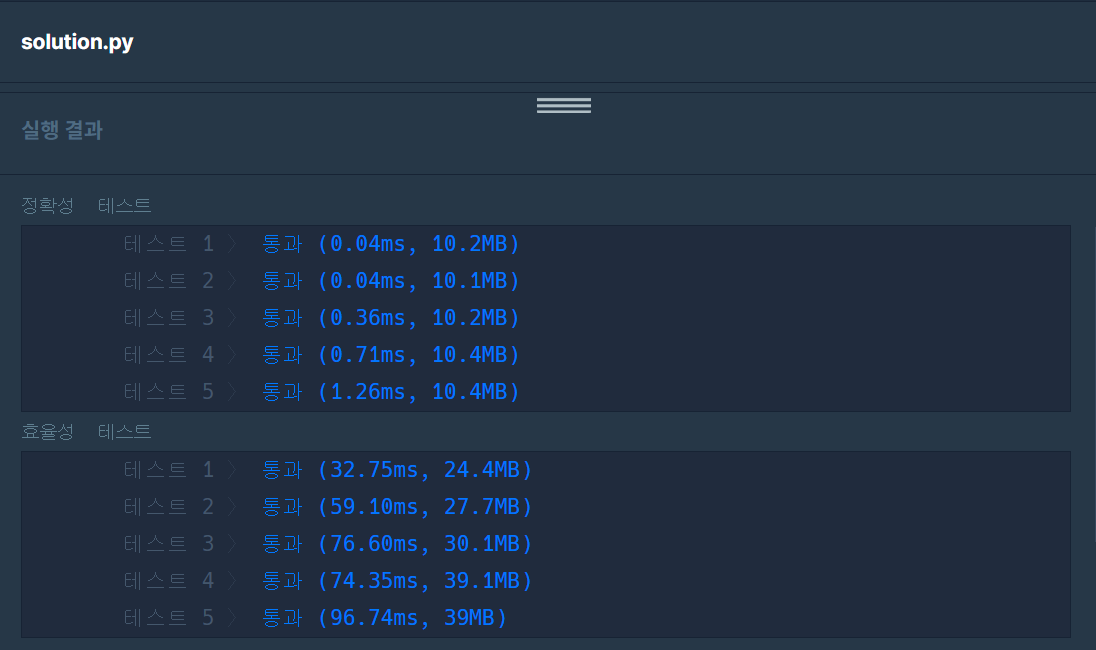
try #4 해시!!! 해시!!! (정확성 통과, 효율성 통과)


각 단어마다, 특정 hash 값이 정해져 있다. 따라서 모든 선수의 hash 값을 더한 후, completion에서 완주한 선수마다 빼면, 남은 hash 값이 완주하지 못한 선수이다.

def solution(participant, completion):
part={}; result=0
for i in participant: part[hash(i)] = i
for i in participant: result += hash(i)
for j in completion: result -= hash(j)
return part.get(result)
정렬보다 훨씬 빠르다.
C++
try #1 그냥 생각해서 짠거
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
string solution(vector<string> participant, vector<string> completion) {
string answer = "";
int i;
for(i=0; i < participant.size(); i++){
if(find(completion.begin(), completion.end(), participant.at(i)) == completion.end())
answer=participant.at(i);
else{
if(count(participant.begin(), participant.end(), participant.at(i)) > count(completion.begin(), completion.end(), participant.at(i)))
answer=participant.at(i);
}
}
return answer;
}테스트케이스 통과 O
효율성 통과 X
try #2 정렬 후 찾기 (테스트케이스 통과, 효율성 통과)
1) 만약 동명이인이 있는데 그중 한명이 완주하지 못했으면, completion과 중간에 다른 부분이 있을 것이다.
또한 정렬된 이름 순에서 중간에 완주하지 못한 선수가 있다면, participant와 completion 탐색 시 중간에 다른 부분이 생긴다.
따라서 반복문으로 participant와 completion에서 다른 부분에서, participant의 요소를 가져온다.
2) 그렇지 않으면, 정렬된 후 participant의 마지막 선수가 들어오지 못한 것. 마지막 요소를 리턴한다.
주의할 점은, 프로그래머스 코드 작성 시 answer이 있는데 그걸 없애고 1)에서 리턴, 2)에서 또 리턴한다.
#include <string>
#include <vector>
#include <map>
#include <algorithm>
using namespace std;
string solution(vector<string> participant, vector<string> completion) {
sort(participant.begin(), participant.end());
sort(completion.begin(), completion.end());
for(int i=0; i<completion.size(); i++){
if(participant[i]!= completion[i])
return participant[i];
}
return participant.back();
}정렬 후 반복문을 돌리니까 확실히 속도면에서 기존의 방법보다 훨씬 빨랐다.

try #3 해시를 사용해서 풀어보고 싶다!!! (정확성 통과, 효율성 통과)
map에 key가 있으면 그 수를 증가시킴(participant)
map에 key가 있으면 그 수를 감소시킴(completion)
만약 두 과정 후 완주한 선수라면 value가 0일 것이고, 동명이인이 있더라도 둘다 완주했다면 0을 가진다.
하지만 완주하지 않은 선수만 value로 값 1을 가지므로, map에서 0보다 큰 value를 갖는 것을 찾고 해당 value를 갖는 key를 리턴한다.
#include <string>
#include <vector>
#include <unordered_map>
using namespace std;
string solution(vector<string> participant, vector<string> completion) {
unordered_map<string, int> m;
for(string key: participant) m[key]++;
for(string key: completion) m[key]--;
for(auto i: m){
if(i.second > 0) return i.first;
}
}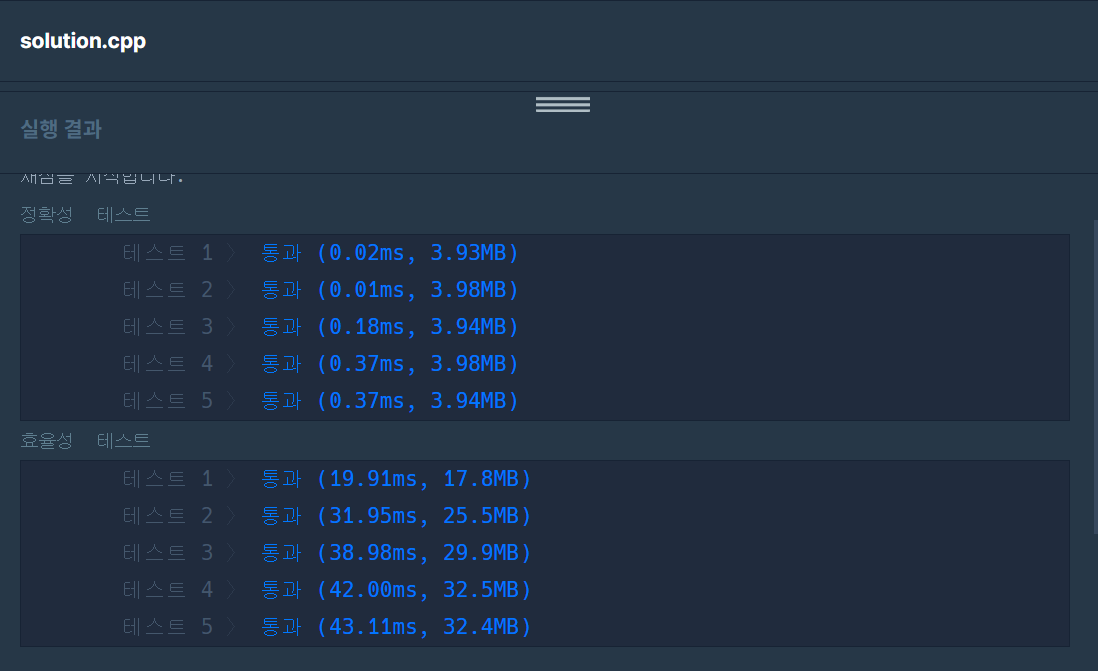
map을 사용할 때가 정렬 후 사용할 때보다 전반적으로 정확성이나 효율성 테스트에서 빨랐다. (체감 검사 속도도 훨씬 빠름)
728x90
반응형
'PROGRAMMING > Algorithm' 카테고리의 다른 글
| [프로그래머스] 모의고사 (완전탐색) (Python, C++) (0) | 2021.01.10 |
|---|---|
| [프로그래머스] K번째수 (정렬) (Python, C++) (0) | 2021.01.08 |
| [HackerRank] Diagonal Difference (Algorithm) (0) | 2021.01.05 |
| [HackerRank] A Very Big Sum (Algorithm) (0) | 2021.01.05 |
| [HackerRank] Simple Array Sum (Algorithm) (0) | 2021.01.04 |




