고정 헤더 영역
상세 컨텐츠
본문 제목
[Paper]DeepFake Detection Based on Discrepancies Between Faces and Their Context
본문

728x90
반응형
MOTIVATION
얼굴 영역 조작 시 컨텍스트는 그대로 두고 컨텍스트에 맞게 얼굴을 조정 → 조작 단서: **두 영역 사이 불일치**
겉으로 identity가 변경되는 얼굴 스왑으로 인한 얼굴 조작의 단서를 찾는 것
가설
A1. 얼굴 조작 방식은 얼굴의 내부 부분만 조작한다.

- 6가지 이미지 모두 얼굴은 조작되었지만 context는 그대로이다.
- (a), (b): 3D morphable model(3DMM)에 해당하는 영역, 즉 상단 이마 일부와 하단 턱 포함하는 얼굴 영역을 조작함
- (c), (d): 정사각형 영역 조작
- (e): 3DMM 기반 입 안쪽 부분을 제외한 얼굴 조작
- (f): 얼굴 분할을 사용한 전체 얼굴 영역 조작
⇒ Motivation 1: 이 얼굴 조작 방법 모두 머리 전체에는 영향을 주지 않음
⇒ 조작된 얼굴 안쪽 영역과 변경되지 않은 외부 context를 비교하여 거짓 이미지 식별하는 signal 제시 -> face identification network와 context recognition network를 학습하여 얼굴 영역과 얼굴 context 영역을 각각 identity 벡터로 표현한 2개의 벡터를 얻고, 두 identity 벡터를 비교하여 **identity-to-identity 불일치**를 찾음
A2. 얼굴의 내부 부분 외에 얼굴의 context(머리, 목, 머리카락 영역)가 대상에 대한 중요한 identity 신호를 제공
RELATED WORK
얼굴 조작 탐지
- descrimintor를 훈련시켜서 실제와 거짓 이미지나 비디오 구별 - MesoNet(Afchar et al.) 등
- 이미지와 비디오에서 splicing manipulation이나 copy-move 탐지 [36], [37], [38], [39]
- 자동 거짓 탐지 방법 개발
- 딥 러닝 기반 연구 (Cozzolino et al. 등) / 다중 단서 활용
- 시간적 단서 사용한 순환 신경망 통해 동영상 조작 탐지 (Sobir et al.)
- backbone classifier의 중간 feature map에 attention 매커니즘 적용하여 조작된 영역 탐지 정확도 향상 (Stehouwer et al.)
- 추가 얼굴 랜드마크 사용 시의 딥페이크 탐지와 localization 향상 보임 (Songsri et al.)
- 적은 수의 파라미터를 사용하면서 캡슐 네트워크 기반 거짓 탐지 아키텍처 제안 (Nguyen et al.)
얼굴 조작 벤치마킹
- FaceForensics
- DeepFake-TIMIT
- CelebDF
- VTD
- FaceForensics++
- DFD
- DFDC
DESIGN
네트워크 → 두 네트워크로부터의 탐지 시그널로 불일치를 탐지
Deep neural network(심층 신경망) 사용
2개의 face recognition network 사용 (face segmentation network, recognition network)
1. Preprocessing: detection & segmentation, cropping faces
1) DETECTION
- DSFD(dual shot face detector) 적용 - DSFD는 얼굴의 좁은 bounding box를 반환하도록 학습되기 때문에 탐지된 bounding box에서 높이를 20% 증가시켜서 얼굴 주변의 context가 더 많이 노출되도록 함
- DFSD(dual shot face detector)
- 얼굴 크기, 포즈, occlusion, 표정, 외형, 조명 등 다양한 변수로 인한 얼굴 조작 탐지가 어려운 문제 해결 위해 SSD(single shot detector)의 아키텍처를 착안하여 원본 feature map을 전송하기 위해 feature enhance module(FEM)을 도입한 탐지 네트워크
- 하나의 이미지 속에 객체의 크기 차이가 큰 경우에도 높은 성능을 갖는 얼굴 검출기
- bounding box
이미지나 비디오 프레임 내 사물을 둘러싸는 bounding box 집합을 예측하여 얼굴 탐지(face와 not-face/backgorund)
2) CROPPING
- 299 x 299 pixel 해상도(Xception 아키텍처의 입력 해상도)로 cropping
3) SEGMENTATION
- face segmentation network
- 사용 목적: face network에서 처리할 부분과 context network에서 처리할 부분 결정
- crop 얼굴을 foreground(얼굴)과 background(context)로 세분화(segmentation)
- 입력: crop된 얼굴 I와 그에 해당하는 face segmentation mask S
- 출력: 각각 얼굴 영역 나타내는 이미지 If와 context 영역 나타내는 이미지 Ic
⇒ 결과: face region If, context region** Ic
2. face swapping artifact 탐지 위한 classifier Es

- 입력 이미지 I를 고려하여 명백한 swapping artifact를 찾아 진짜 face swapping 결과인지 여부 vs를 결정하는 네트워크
3. Recognition Network
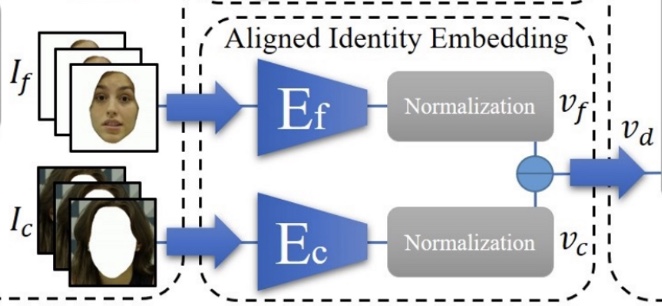
- Ef face recognition Network
- 얼굴 영역 픽셀 포함하는 299 x 299 해상도의 이미지를 데이터셋 얼굴 ∗∗If∗∗과 관련된 의사확률 벡터 vf로 매핑하는 face recognition 네트워크
- ∗∗Ec context recognition network**
- detection bounding box의 나머지 픽셀에 해당하는 context Ic와 관련된 의사확률 벡터 vc로 매핑하는 context recognition 네트워크
4. Classification/ Fake Detection

- vf와 vc는 서로 빼고 Es 결과인 vs와 결합하여 최종 classifier D로 전달되고, classifier는 해당 이미지가 Real인지 Fake인지 식별한다.
Face Discrepancy network - 얼굴 불일치 요소 학습
Ef 와 Ec 네트워크 출력인 vf와 vc를 사용하여 face와 context가 서로 동일한 identity를 공유하는지 예측하도록 학습
face 이미지 If와 context 이미지 Ic를 2개의 identity classifier인 Ef와 Ec에서 처리했다고 했을 때 불일치 feature vector vd는 다음과 같다:
> vd =Ef(If)−Ec(Ic)=vf−vc
>
Manipulation specific networks
이전 Face Discrepancy network는 swapping이나 reenactment(재연)과 같은 특정 조작을 고려하지 않고 실제 얼굴과 가짜 얼굴을 구별하도록 classifier를 학습했다. 이 swapping이나 reenactment의 두 가지 조작은 모두 얼굴의 5가지 identity를 조작하는데, reenactment는 얼굴 포즈와 표현도 조작한다. reenactment은 중점을 두는 얼굴 조작 기법이 아니지만 FaceForensics++ 벤치마크에서 요구되는 기능이기 때문에 얼굴 재연 탐지를 위한 구성 요소도 포함하였다.
face swapping과 reenactment 각각에 대해 별도의 전용 classifier인 Es와 Er을 학습시켜서 swapping과 reenactment를 분리하였다.
(1) Es 네트워크

face swapping artifact 탐지 classifier Es
- swapping artifact 탐지하도록 학습
(2) Er 네트워크
- reenactment artifact 탐지하도록 학습
- Method Overview에는 표시되어있지 않음
- ∗∗Er 네트워크는 face swapping과 face reenactment가 모두 탐지된 경우에만 사용되고, 그렇지 않으면 3개의 network만 사용한다.**
모든 detection cue 결합 (concatenation)
- 다양한 signal을 결합하기 위해 vd,vs,vr의 세 벡터를 연결(concatenatation)하는 방식 사용
- vd∈R8631
- vs=Eps(I),vr=Epr(I) ( vs,vr∈R2048 에서 Es 와 Er의 두 번째 층의 activation 나타냄
- 연결된 벡터는 logistic loss 함수 사용하여 학습된 classifiser D로 전달
Inference images
- 여러 얼굴이 포함된 이미지 처리 시 감지된 얼굴 중 높이가 64 픽셀보다 큰 얼굴만 분류하고 나머지는 배경 얼굴로 버림
- 가장 큰 얼굴이 높이 64 픽셀보다 크지 않은 경우 감지된 얼굴 중 가장 큰 얼굴을 처리
- 잘못된 검출 제거
- 각 검출에 대해 face segmentation mask의 얼굴 픽셀 수(S)에 임계값을 적용.
- crop된 영역의 픽셀 수에 비례하여 15% 임계값으로 시작하고, 모든 감지를 필터링하면 임계값을 절반으로 줄임.
- 7.5% 임계값을 통과하는 이미지가 하나도 없는 경우 감지된 픽셀 수가 최대인 얼굴 패치 하나만 고려
- 나머지 얼굴 패치에 복합 네트워크 적용하여 얼굴 패치당 하나의 점수를 D 출력으로 얻음
- 얼굴이 하나만 조작된 경우 점수의 최소 출력(가짜일 가능성이 가장 높은 것으로 예측된 얼굴 패치) 사용
---
IMPLEMENTATION
face segmentation network
- 업샘플링 단계에서 사용되는 deconvolution layer에 선형 보간과 convolution으로 대체된 U-Net 아키텍처 사용
- crop: 256 x 256 해상도로 자르고 크기 조정
- 학습에 사용한 데이터셋: face segmentation 데이터셋 (Nirkin et al.에서 사용한 것과 유사하고 오픈소스 코드 사용하여 데이터셋 생성함)
- 학습 반복회차: epoch 당 40.000회
- 학습 batch size: 48
- 네트워크 robustness 높이기 위해 image augmentation(이미지 증강) 적용
- -30 ~ 30도 사이 무작위 이미지 회전, 무작위 색상 지터링(밝기, 대비, 채도, 색조), 0.5 확률의 수평 뒤집기, 커널 크기 5, 시그나 1.1의 gaussian blur(0.5 확률로 적용) 등
recognition network
- 네트워크 아키텍처: Xception 아키텍처
- Xception의 Inception 모듈을 depth-wise separable convolution 연산으로 대체 (이 depth-wise separable convolution은 face recognition에서 사용된 적이 없음)
- convolution

- depth-wise separable convolution

- depthwiseconvolution: filtering stage → standard convolution 연산에서는 한 개의 필터가 M채널 전체에 convolution 연산을 하는데, depthwise convolution 연산은 한 개의 필터가 한 개의 채널에만 연산
- p∮wiseconvolution: combination stage
- Xception 네트워크는 strided convolution block과 마지막 블록 제외한 residual connection을 가진 12개의 depth-wise separable convolutions block으로 구성되며, 2개의 depth-wise separable convolution, pooling 연산과 fully connected layer으로 끝남
- 손실 함수: vanilla cross entropy loss → 네트워크 학습에 사용
- 학습 네트워크: Ef Ec의 2개의 recognition network (face recognition network, context recognition network)
- 네트워크 학습 데이터셋: VGGFace2 데이터셋
→ 128 x 128 해상도보다 낮은 해상도의 이미지 필터링해서 8,631개의 identity 도출
⇒ Ec Ef 네트워크 출력: R 8,631
Training
- Adam optimization 적용
- 학습 시 C32(HQ)와 C40(LQ)로 압축된 비디오 사용 → C23 압축 비디오와 거의 차이가 없기 때문에 raw 비디오 사용하지 않음
- 4개의 네트워크가 훈련되면 Ef와 Ec의 가중치를 동결하고 출력 벡터 (vs,vr,vd)를 사용하여 최종 classification network인 D를 훈련시키면서 Er과 Es의 가중치만 미세 조정한다.
- learning rate: 10 epoch마다 반씩 감소 → 초기 learning rate와 batch size는 training stage마다 다름
- Es**, Er, Ef, Ec를 pre-training**
- manipul;ation specific network인 Es와 Er 의 pre-training은 FaceForensics++로 epoch 당 반복회차 40,000회 학습 진행. back size는 96이며 learning rate는 0.0002.
- **identity network Ef, Ec training**
- 학습에 사용한 데이터셋: VGGFace2
- bounding box에서 두 축 중 더 긴 축을 20% 길이 늘리고 크기 확장해서 crop하고 299 x 299 해상도로 크기 재조정
- 0.5 확률로 수평으로 뒤집음
- Ef는 context pixel을 일정한 색상으로 설정하고, Ec 는 얼굴에 해당하는 pixel을 일정한 색상으로 설정
- 두 네트워크 모두 batch size 192 learning rate 0.0002로 학습
- **최종 학습**
- FaceForensics++ 비디오의 동일한 분할에 대해 수행
- Es, Er, D 네트워크가 학습되고 identity network인 Ef와 Ec의 가중치가 동결된다.
- Es 학습
- face swapping 방법인 FaceSwap과 DeepFake로 조작된 FaceForensics++의 하위 비디오로 학습
- Er 학습
- face reanactment방법인 Face2Face와 NeuralTextures로 조작된 비디오로 학습
- discriminator D
- scratch에서 학습
- normal distribuytion을 사용하여 랜덤으로 초기화한 가중치를 사용
- batch size: 64
- learning rate 0.0001
- 20,000 iterations per epoch
---
EVALUATION
1. recognition 네트워크의 인식 정확도 검증
- 데이터셋: VGGFace2, Faces in the Wild(LFW) 벤치마크
→ 이때 LFW 이미지 테스트 전에는 네트워크에 추가 학습이나 fine tuning 하지 않음
- 결과 #1 Face recognition 정확도 (VGGFace2)
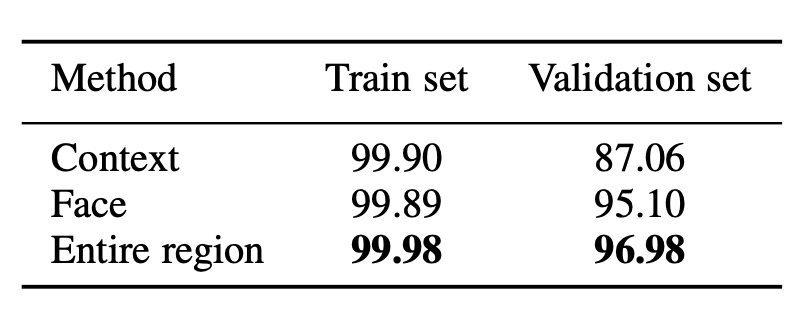
- 얼굴과 context가 모두 포함된 전체 영역에서 가장 정확도가 높았다. 주목할만한 점은, Context만으로도 얼굴 식별을 위한 강력한 단서를 제공하고 있음을 알 수 있다.
- 결과 #2 identification 네트워크의 검증 정확도 (LFW)

- (a) Xception 아키텍처의 최종 layer에서 얻은 결과
- (b) Xception의 두 번째 layer의 activation을 사용하여 표현된 얼굴.
얼굴 인식 네트워크의 두 번째 계층의 활성화가 두 네트워크에서 독립적으로 학습하였기 때문에 동일한 사람에 대해 잘 일치하지 않는 결과를 보이므로, 두 네트워크의 response 결합 시 최종 출력인 의사확률(pseudo-probabilities)을 사용
Face swapping detection 실험
face swapping만 있는 데이터셋 사용
- FF-DF: Faceforensics++ 내에서 face swapping 만 포함한 데이터셋으로, 깨끗한 비디오 1000개와 딥페이크 비디오 1000개 포함
- DFDC: 66명의 배우가 출연한 총 5,244개의 동영상이 포함되어 있으며 4,464개의 트레이닝 비디오와 780개의 테스트 비디오 중 1,131개는 실제 비디오이고 4,113개는 알려지지 않은 두 가지 다른 얼굴 스와핑 방법으로 생성된 가짜 비디오
- Celeb-DF-v2: 59명의 유명인에 대한 590개의 실제 동영상과 5,639개의 딥페이크 동영상이 포함
학습 방법
- Er (reenactment) 네트워크 사용 X
- 학습에 사용한 데이터셋: FaceForensics++
평가지표
- AUC
실험결과

- 모든 벤치마크에서 최고 AUC 점수 얻음
- FF-DF에서는 정확도가 포화 상태에 이르렀기 때문에 우리의 방법은 현재 기술과 비슷한 결과를 얻은 것 확인 가능
- 까다로운 Celeb- DF-v2 벤치마크에서는 AUC 점수가 조금만 개선되어도 큰 차이를 보이며, Celeb-DF-v2에 대해 보고된 결과는 기본 방법과 비교하여 일반화 능력이 향상되었음을 입증
FaceForensics++ 실험
사용 데이터셋
- Faceforensics++
- 웹에서 수집한 1000개의 비디오가 포함되어 있는데, 무작위 1000개 비디오 쌍을 선택하고 4가지 얼굴 조작 방법 대표하는 1000개의 추가 조작된 비디오 생성하는데 사용
- 4가지 얼굴 조작 방법 중 3D 기반 face swapping 방법과 GAN 기반 방법에 대해서는 피사체의 이미지 쌍 사용하여 둘 사이 매핑 계산
- 추가 2개 얼굴 조작 방법에는 face reenactment 적용
- Face2Face: 얼굴에서 추정된 표정 계수 변경하여 얼굴을 조작하며 3DMM 기반 방법
- NeuralTextures: 비디오에서 얼굴 신경 텍스처를 학습하고 이를 사용하여 3D로 재구성된 얼굴 모델을 사실적으로 렌더링하는 방법
실험결과
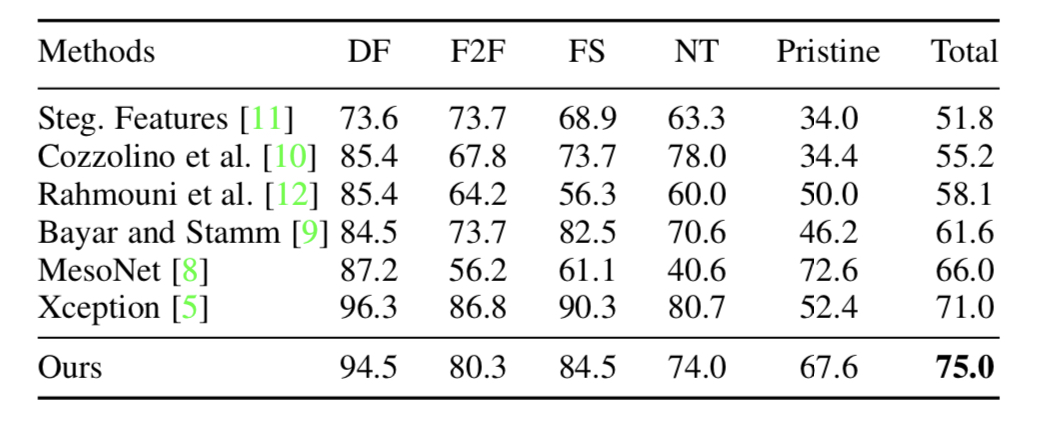
- 제안하는 얼굴 조작 탐지 방식이 대부분의 기존 연구보다 높은 정확도를 보임 (모든 기존 연구보다는 성능이 좋지는 않음)
- 저자는 실제 이미지와 가짜 이미지의 정확도 사이에는 임계값에 따른 trade-off가 있어 정확도 자체만으로는 탐지 성능을 직접적으로 나타내는 것은 아니라 주장
Ablation study & 일반화 실험
실험내용
- training set에 포함되지 않은 방법으로 생성된 거짓을 제안된 방식의 탐지 정확도 검증 실험
사용 데이터셋

- Faceforensics++ 데이터셋에 FSGAN과 Nirkin et al.이 제안한 3D 기반 face swapping 방법 2가지의 face swap 방법 적용
- Fig. 5는 동일한 source와 target을 사용하는 4가지 face swap 방법이며, FSGAN을 제외하고는 뚜렷한 artifact를 생성하고 있는 것 확인할 수 있음
일반화 실험 설계
-데이터셋: Faceforensics++ 하위 집합의 원본 및 얼굴 조작 데이터
- 데이터셋 사용하여 제안된 방법과 XceptionNet baseline을 학습
- Er 네트워크 사용 X
일반화 & ablation study 실험결과
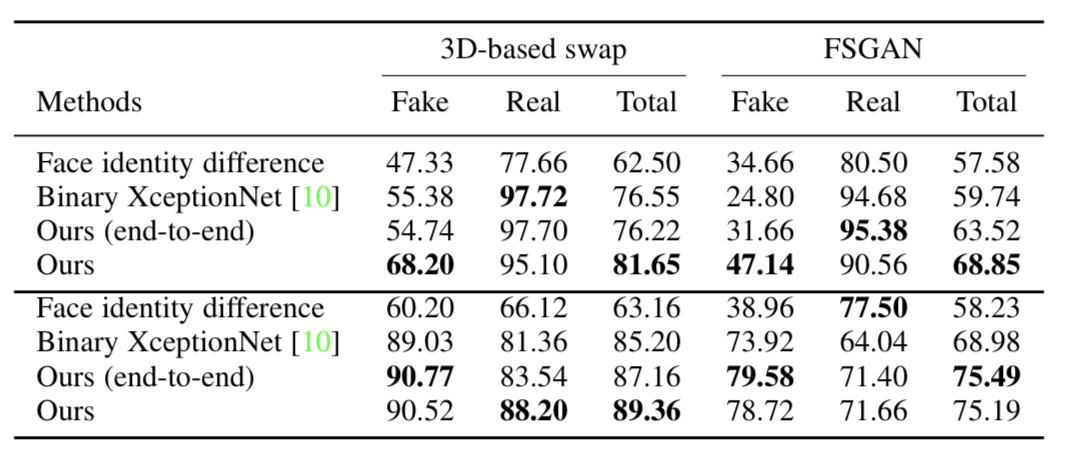
- 학습 시 classifier가 고정되지 않은 end-to-end 방식으로 학습
- 표 4의 맨 위에 표시된 결과의 경우, XceptionNet과 제안 방법의 임계값을 0으로 고정하였고, 하단에서는 테스트 세트에서 두 임계값을 모두 최적화
- 첫 번째 실험에서 얼굴 identity 차이의 임계값은 VGGFace2 테스트 세트를 사용하여 최적화
- unseen methods에서 모두 기준을 능가하는 성능 보임
- 아티팩트가 더 드물게 생성되는 FSGAN 생성 얼굴에서 성능 격차가 더 크고 3DMM 기반 방법으로 생성된 아티팩트는 다른 방법에서 발생하는 아티팩트와 더 유사하므로 그 격차가 더 작음

- ROC 곡선에서 확인할 수 있듯이 제안된 방법의 end-to-end 버전의 방법은 일반화 능력이 떨어지는 이유: end-to-end 학습 과정에서 얼굴 및 context classifier가 정렬된 identity 표현을 추출하는 역할을 제대로 수행하지 못하기 때문
- face discrepancy signal 자체는 가짜를 탐지하도록 학습된 네트워크와 경쟁력이 없음
정성적 결과

그림 7은 DFDC 데이터셋에서 탐지된 가짜 얼굴과 탐지되지 않은 가짜 얼굴의 정성적 예시이다.
그림 (a)
- 제안된 방법으로 탐지되었지만 XceptionNet 가짜 검출기로는 탐지되지 않은 가짜 얼굴의 예
그림 (b)
- XceptionNet에서는 탐지되었지만 제안된 방법에서 탐지되지 않은 가짜 얼굴의 예시
- XceptionNet에서 탐지한 가짜 얼굴에 눈에 보이는 artifact가 나타나는데, 이는 XceptionNet 방법이 이를 탐지하는 데 최적화되어 있음을 알 수 있음
- 제안된 방법의 경우 유사한 방법별 artifact를 탐지하도록 학습된 face swapping component인 Es가 포함되어 있지만, (b)의 artifact가 존재할 때 기준선과 동일한 탐지 정확도를 제공하지 않음
그림 (c)
- 두 approach에서 모두 놓친 가짜 얼굴의 예시
LIMITATION & CONCLUSION
Conclusion
1. face swap을 식별하는 새로운 접근 방식 제안
2. 최근 모든 얼굴 identity 조작 방법에서의 공통점 활용한 새로운 탐지 단서 제안하였고, 기존 연구의 classifier 보완하여 함께 사용 가능
3. FaceForensics++, Celeb-DF-v2, 그리고 DFDC에 적용했을 때 기존 제안된 방법보다 성능이 뛰어남
728x90
반응형
'ANALYSIS > Paper Review' 카테고리의 다른 글
anonymous?koharin 님의 블로그입니다.




