고정 헤더 영역

상세 컨텐츠
본문

728x90
반응형
Scalable Diffusion Models with Transformers 논문은 2023년 ICCV에 발표되었으며, 본 글 작성일 기준 515회 인용되었습니다.
Background

1. Diffusion
- Forward process (q)
- 실제 데이터 x_0에 점진적으로 noise 적용하여 latent variable x_t 생성하고, 최종적으로 noise x_T 를 생성
- q(x_t ┤| x_0)= N(x_t; √((α_t ) ̅ ) x_0, (1-(α_t ) ̅ )I)
- 샘플링: x_t=√((α_t ) ̅ ) x_0+ 〖√(1 - α ̅ )〗_t ϵ_t, where ϵ_t ~N(0,I) (reparameterization trick 적용)
- Reverse process (p)
- Forward process 정보 활용하여 NN 이용한 p_θ (x_(t-1) |x_t) 학습하여 noise(x_T)로부터 데이터(x_0) 복원
- q(x_t ┤| x_0)가 주어졌을 때, q 확률 분포를 잘 모델링하는 확률 분포 p_θ를 학습 -> p_θ (x_(t-1)│x_t ) :=N(μ_θ (x_t ), ∑2_θ(x_t,t))
- Loss Function: L(θ)=-p(x_0│x_1 )+ ∑_t▒〖D_KL (q^∗ (x_(t-1)│x_t, x_0 ) 〗∥p_θ (x_(t-1) |x_t))
- 학습된 reverse process 공분산 ∑_θ로 diffusion model 학습 시 전체 D_KL항 최적화 필요-> ADM 접근방식을 따라 L_simple로 ϵ_t 학습하고 전체 L로 ∑_θ학습, 샘플링: x_(t-1) ~ p_θ (x_(t-1), x_t)
2. DDPM(Denoising diffusion probabilistic models)
- 기존 diffusion model이 고품질 샘플 만들지 못하는 문제 해결 위해 제안
- Forward process
- q(x_t ┤| x_(t-1))= N(x_t; √(1-β_t ) x_(t-1), β_t I) -> trainable parameter였던 α_t 을 constant variable β_t 로 고정
-> q에 학습 파라미터 없어 학습 없음 -> first loss term(L_T) 무시 가능
- q(x_t ┤| x_(t-1))= N(x_t; √(1-β_t ) x_(t-1), β_t I) -> trainable parameter였던 α_t 을 constant variable β_t 로 고정
- Reverse process
- 샘플링 시, gaussian distribution 분산을 설정
- σ_t^2= β_t à x_0가 N(0,I)로 최적화
- σ_t^2= (β_t ) ̃= (1 - (α_(t-1) ) ̅)/(1-(a_t ) ̅ ) β_t -> one point로 최적화
- reparameterization 이용해서 loss 함수 디자인
- 특징
- U-Net을 백본 아키텍처로 사용
3. Classifier-free guidance
- 기존 diffusion model과 차이점
- 클래스 레이블 c와 같은 추가 정보를 입력으로 사용
- Reverse process
- c가 조건부인 p_θ (x_(t-1)│x_t, c) 사용 à log〖p(x|c)〗가 높은 x를 찾도록 샘플링 절차 유도 가능
- 샘플링
- (ϵ_θ ) ̂(x_t,c)= ϵ_θ (x_t,∅)+s∙∇_x log〖p(x│c)〗 ∝ϵ_θ (x_t,∅)+s∙(ϵ_θ (x_t,c) -ϵ_θ (x_t,∅))
- 일반 샘플링 기술보다 개선된 샘플 생성함
=> Classifier-free guidance의 샘플링 기술은 DiT에도 적용함
4. Latent diffusion models
- 고해상도 픽셀 공간에서 diffusion model 학습이 어려운 문제 해결
- two-stage approach
- 학습된 인코더 E 사용하여 이미지를 더 작은 공간 표현으로 압축하는 autoencoder 학습
- 이미지 x의 diffusion model 대신 표현 z = E(x)의 diffusion model을 학습
-> 표현 z 샘플링 à x = D(z)로 이미지 디코딩하여 새로운 이미지 생성
- 샘플링
- Diffusion model에서 표현 z 샘플링
- Decode
- 학습된 decoder x = D(z) 사용하여 이미지로 디코딩 à 새로운 이미지 생성
=> DiT의 경우, ADM과 같은 pixel space diffusion model보다 훨씬 적은 Gflops 사용 & 우수한 성능 달성
5. Vision Transformer(ViT)
- 특징
- Convolutional network 구조를 transformer 구조로 대체
- 이미지 자체를 transformer에 직접적으로 넣어주는 형태로 모델 구성
- 충분한 크기의 데이터셋에서 사전학습 후, 적은 데이터셋 가진 작업에 전이 학습 시킬 때 좋은 성능을 보임
- 입력 임베딩
- 이미지를 patch 단위로 쪼개 토큰화함(토큰 시퀀스 형태)
- Patch에 linear embedding 적용하여 만들어진 임베딩 patch를 transformer 입력으로 넣어줌
=> Diffusion model은 noisy image, noise timestep, class label, 자연어 등 처리하므로, 본 연구에서는 ViT block 디자인을 변형하여 transformer block 구현
Approach
기존 Diffusion Model 연구
- Diffusion Model은 대부분 U-Net을 백본으로 사용함
- DDPM에서 처음으로 백본으로 U-Net 사용이 제안되었음
- 이후 제안되는 diffusion model 연구에서도 U-Net 설계 유지
=> 본 연구에서는 U-Net의 inductive bias가 diffusion model의 성능에 결정적이지 않으며, transformer 설계로 대체할 수 있음을 보임
Diffusion Transformers(DiTs) Architecture
- 이미지의 공간적 표현의 DDPM을 학습하는데 중점을 두기 때문에, DiT 모델은 patch 시퀀스에서 작동하는 vision transformer 아키텍처를 기반으로 함
- 새로운 아키텍처인 diffusion transformers 제안
- 표준 transformer 아키텍처에 스케일링 속성 유지
- 이미지의 ddpm 훈련하는데 중점
- Patch의 sequence에서 작동하는 ViT 아키텍처 기반으로 함
- Left: conditional latent DiT model 학습. Input latent는 patch로 분해되어 여러 개의 DiT 블록으로 처리됨
- Right: DiT 블록의 세부구조로, adaptive layer norm, cross-attention과 input token을 통해 컨디셔닝을 통합하는 표준 transformer 블록 변형 실험해봤을 때 adaptive layer norm이 가장 성능이 좋았음
Methodology
1. Patchify


- 첫 번째 레이어, 이미지를 transformer 입력에 넣도록 변환하는 역할
- ViT에서 다루는 개념
- 입력에 각 patch를 linear embedding하여 공간 입력을 각각 차원 d의 T (Txd shape) 토큰 시퀀스로 변환
- 토큰 T 수: p(patch size) 파라미터에 의해 결정 (논문에서는 p= 2,4,8)
- Patch size: p x p
- 입력 토큰에 ViT frequency-based positional embedding 적용
-> 입력 이미지 내 patch 위치 맞춤
2. In-context Conditioning

- 입력 시퀀스에 timestep(t)와 conditioning(c) 임베딩 추가
- Embed layer: SiLU activation 적용 & 출력 dimension 256인 2개의 MLP 구성
- ViT의 cls 토큰과 유사하여 ViT 블록 수정없이 사용 가능
- 최종 블록 이후 시퀀스에서 c 토큰 제거
- 모델에 무시할 수 있는 수준의 Gflops 사용
3. Cross-attention Block
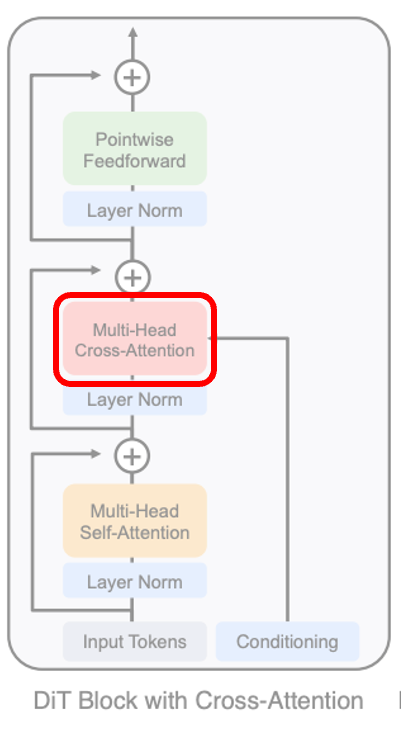
- timestep t와 c(conditioning) 임베딩을 길이 2의 시퀀스로 연결
- Transformer block을 multi-head self-attention block 뒤에 multi-head cross-attention이 위치하도록 수정
- attention 설계와 LDM의 class label에 대한 conditioning과 유사
- 가장 많은 Gflops 추가 à 모델에 약 15%의 오버헤드 추가
4. Adaptive layer norm(adaLN) block

- Transformer 블록 내 표준 layer norm 레이어를 daptive layer norm(adaLN)으로 대체
- 차원별 스케일 파라미터 γ와 shift 파라미터 β를 직접적으로 학습 X
-> t와 c의 임베딩 벡터 합으로부터 회귀하여 이를 shift와 scale 값으로 활용 - 장점
- 가장 적은 Gflops를 추가 -> 컴퓨팅 효율 가장 높음
- 모든 토큰에 동일한 함수 적용하도록 제한하는 유일한 컨디셔닝 메커니즘
6. adaLN-Zero block

- ResNet 연구에 따르면, 각 블록의 마지막 batch norm scale factor를 0으로 초기화 시 지도학습 환경에서 대규모 학습이 가속화된다는 사실 발견
- DiT 블록 내 모든 residual block 연결 직전에 적용되는 차원별 스케일링 파라미터 α도 회귀시킴
- α 의 초깃값이 zero
- adaLN-zero로 이름 붙임
- MLP를 α 에 대해 zero vector 출력하도록 초기화 -> 전체 DiT block이 identity function로 초기화
- 무시할 수 있는 Gflops 추가
모델 크기에 따른 4가지 DiT 사용

- DiT-S(Small), DiT-B(Base), DiT-L(Large), DiT-XL(XLarge)
Transformer Decoder
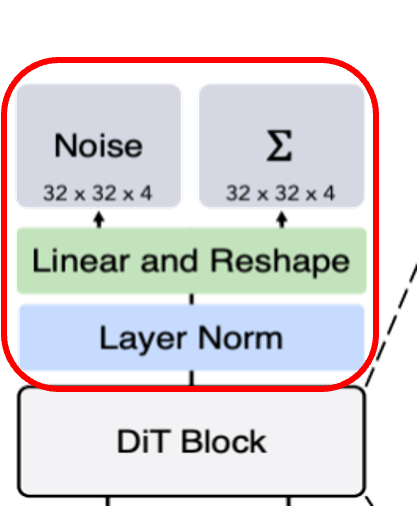
- 최종 DiT 블록 이후, 이미지 토큰 시퀀스를 출력 노이즈 예측과 출력 대각 공분산 예측으로 디코딩
- 표준 선형 디코더 사용해 layer norm 적용하고 각 토큰을 pxpx2C 텐서로 디코딩
- C: DiT에 대한 공간 입력의 채널 수
- 디코딩된 토큰을 원래의 공간 레이아웃으로 재배열 -> 예측된 노이즈, 공분산 얻음
Experiments
Experiment Setup
- Training
- 데이터셋: ImageNet(256x256, 512x512)
- 최종 linear layer: 0으로 초기화 or ViT의 표준 가중치 초기화 기법 사용
- Optimizer: AdamW
- Learning rate: 0.0001
- Weight decay: X
- Batch size: 256
- Data augmentation: horizontal flip
- EMA decay: 0.9999
- ADM에서 가져와서 학습 파라미터 사용
- TPU-v3, TPU v3-256 pod 이용하여 학습 진행
- Diffusion
- VAE: Stable Diffusion의 pre-trained VAE 사용
-> RGB 이미지 x를 32x32x4의 공간 표현인 z로 다운샘플링 - t_max=1000
- Noise schedule: 선형, 1×〖10〗^(-4)에서 2×〖10〗^(-2)
- VAE: Stable Diffusion의 pre-trained VAE 사용
- Metrics
- FID
- 스케일링 성능 측정
- 작은 구현 디테일에 민감함
- FID
DiT Block

- Conditioning 전략에 따른 FID-50K
- adaLN-Zero가 cross-attention, in-context conditioning block을 모든 학습 stage에서 성능↑
- 특히 vanilia adaLN 능가함
Model Size, Patch Size
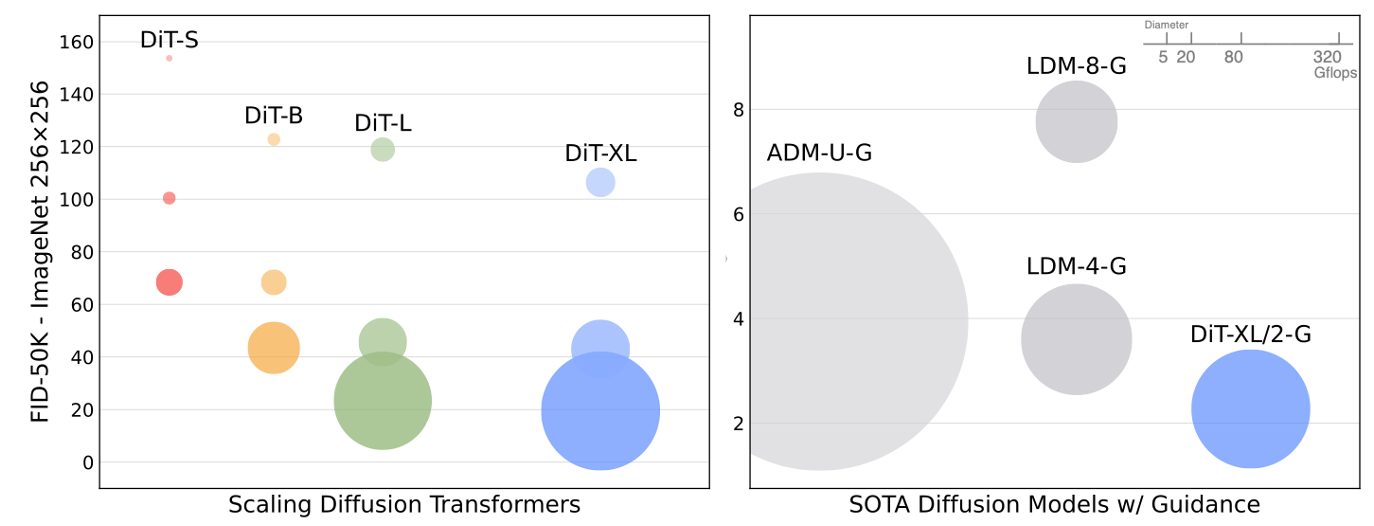
- 모델 구성(S,B,L,XL)와 patch 크기(8,4,2) 조합 12개의 DiT 모델 학습 결과
- 모델 flop이 증가함에 따라 FID 성능이 향상됨
- 모델 크기 DiT-XL/2가 컴퓨팅 효율성이 뛰어나며, U-Net 기반의 ADM, LDM보다 성능이 뛰어남

- 모델 구성(S,B,L,XL)과 patch 크기(8,4,2) 조합 12개의 DiT 모델에 따른 FID 결과
-
Transformer가 깊고 넓을수록 FID가 개선됨
-
처리되는 토큰 수를 확장하고 파라미터를 거의 고정했을 때 FID가 개선됨
-
DiT Gflops

- 모델 Gflops에 따른 FID-50K 비교
- Gflops가 비슷한 경우, 서로 다른 DiT 구성이 비슷한 FID 결과를 보임
-> 모델 Gflops와 FID-50K 간에 강한 음의 상관관계가 있음
- Gflops가 비슷한 경우, 서로 다른 DiT 구성이 비슷한 FID 결과를 보임
Large DiT Model

- Larger DiT Model, more compute-efficient
-
작은 DiT 모델은 오래 학습해도 적은 단계로 학습한 큰 DiT 모델보다 컴퓨팅이 비효율적
-
XL/4에서 약 1010 Gflops 이후 XL/2보다 성능이 뛰어남
-
ImageNet

- DiT XL/2 모델에서 256x256, 512x512 image size의 FID, IS 결과
-
256x256, 512x512 이미지 사이즈 모두 FID, IS가 다른 diffusion model보다 성능이 좋음
-
Scaling Model vs. Sampling Compute

- 샘플링 시 사용되는 Gflops에 따른 FID
-
소형 모델에서 많은 Gflops으로 샘플링해도 대형 모델과 성능 격차 좁힐 수 없음
-
Conclusion
- Diffusion Model의 U-Net에서 Transformer로 교체한 DiT 모델 제안
- DALL-E 2, Stable Diffusion 과 같은 text-to-image 모델의 백본으로 사용할 수 있음
Discussion

- 실용성을 입증함
- SORA(OpenAI)는 Diffusion Transformer를 기반 모델로 사용함
-> DiT가 비디오 모델로서도 효과적으로 확장될 수 있음을 보임 - 훈련 컴퓨팅이 증가함에 따라 샘플 품질이 현저하게 향상됨을 보임
- SORA(OpenAI)는 Diffusion Transformer를 기반 모델로 사용함
728x90
반응형
'ANALYSIS > Paper Review' 카테고리의 다른 글
anonymous?koharin 님의 블로그입니다.




